11 tidyr e dplyr
este capítulo está em construção. O que segue abaixo é apenas um rascunho.
11.1 Introdução
Neste capítulo, descreverei os fundamentos e operações da manipulação de dados. Falo como aplicá-las usando os pacotes “dplyr” e “tidyr”.
11.2 Importing e Wrangling
11.2.1 Importing
Não tem muito erro, tem que saber como são os formatos de arquivo que existem. Veja o ex 5 da lista 4 do trainee.
Cada arquivo, a depender do seu tipo, tem configurações diferentes. Ex: um arquivo CSV pode ser separado por , ou ;, qual a planilha quista de um .xlsx. Esse tipo de configuração precisa ser passada para a função que lê o arquivo.
Também podemos estar interessados em:
- Pular linhas e colunas.
- Definir tipos das colunas.
- Especificar o que define strings (ex
'ou"), comentários (ex#), e valoresNA.
11.2.2 Tidy Data
Antes de falar sobre tidying, vamos falar sobre o que é um dataset tidy.
Veja a aula 4 do trainee.
Para ciência de dados, será útil utilizar uma organização específica, chamada de “tidy dataset”. Três regras a definem:
- Cada variável deve ter sua própria coluna.
- Cada observação deve ter sua própria linha.
- Cada valor deve ter sua própria célula.
11.2.3 Tidy Data

Quais os benefícios?
- A consistência de utilizar uma mesma organização, independente de qual, é muito útil, especialmente porque facilita entender as ferramentas que trabalharão com ela.
- A arrumação tidy é intuitiva, e é utilizada de maneira muito natural nas ferramentas, muitaz vezes vetorizadas, de visualização e modelagem.
11.2.4 Tidying
- Agora que já entendemos o que é tidy data, podemos adquirir a habilidade de olhar para um dataset e, sabendo onde queremos chegar, elencar quais são as alterações a serem feitas.
- Após elencar quais alterações devem ser feitas, é simples fazer a ponte de quais manipulações de dados você quer fazer – “subset linhas” e “separar colunas”.
- Por fim, só falta relembrar como é o código que aplica essa manipulação. Essa é a parte mais simples! É só voltar na aula passada, pesquisar na internet, ver no chat, ou perguntar para o seu amigo preferido!
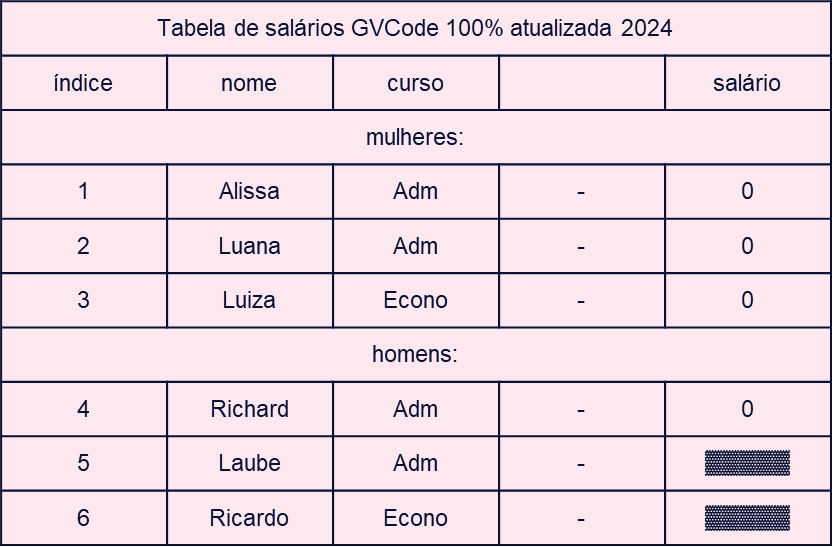
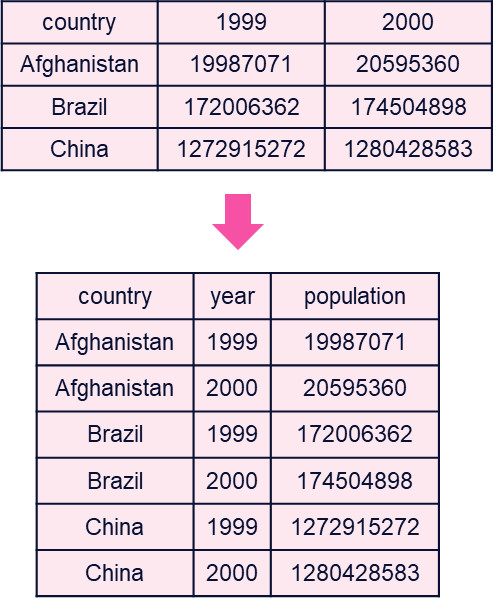

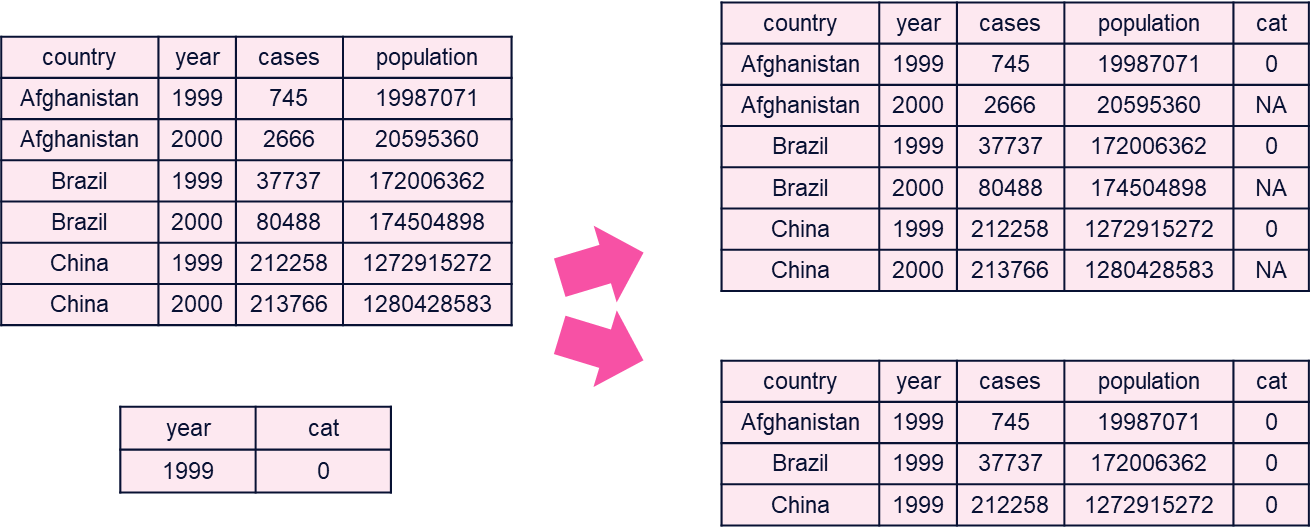
11.2.10 Tidying: Receita
Qual foi a receitinha de bolo que aprendemos? (hmm bolo 😋). Recebemos um dataset, e:
- Arrumar os dados para o formato data frame.
- Todas as colunas são homogêneas?
- Remover linhas “ruins”, converter valores.
- Todas as colunas são do mesmo tamanho?
- Remover linhas “ruins”.
- Todas as colunas são homogêneas?
11.2.11 Tidying: Receita
- Arrumar os dados para o formato tidy.
- Toda coluna é uma variável?
- Remover colunas “ruins”.
- Separar/unir colunas colunas.
- Toda linha é uma observação?
- Quais são as variáveis que definem uma observação?
- Pivot e melt.
- Toda coluna é uma variável?
11.2.12 Tidying: Receita
- Dados NA.
- Transformar dados “ruins” em NA.
- Lidar com dados NA.
- Tenho mais de um dataset? Deixá-los tidy e então realizaram algum merge.
11.2.13 Transforming
Após arrumarmos um dataset, ainda aplicaremos transformações com base nas demandas da fase de visualização e modelagem.
- Manipular linhas.
- Sorting.
- Sampling.
- Filtrar observações.
11.2.14 Transforming
- Transformar/criar colunas:
- Alterar a unidade de uma variável.
- Normalizar variáveis.
- Agrupar as categorias de uma variável categórica.
- Corrigir/formatar texto de variáveis string.
- Manipular datas.
- Criar novas colunas a partir de operações com múltiplas outras.
- Criar uma coluna para ajudar em um plot.
11.3 tidyr
O tidyr existe “to help you create tidy data”.
Veja:
- O tutorial.
- A cheatsheet.
Aqui, temos as caixinhas:
- Reshape (pivot)
- Separate/unite
- NA handling (+ complete)
- Outros: lists to dataframes (unnest)
11.3.1 Separate
df <- tibble(id = 1:3, x = c("m-123", "f-455", "f-123"))
df %>% separate_wider_delim(x, delim = "-", names = c("gender", "unit"))
df %>% separate_wider_position(x, c(gender = 1, 1, unit = 3))
df %>% separate_wider_regex(x, c(gender = ".", ".", unit = "\\d+"))
#> # A tibble: 3 × 3
#> id gender unit
#> <int> <chr> <chr>
#> 1 1 m 123
#> 2 2 f 455
#> 3 3 f 12311.3.2 NA Handling 1
df <- tibble(x = c(1, 2, NA), y = c("a", NA, "b"))
df %>% drop_na(x)
#> # A tibble: 2 × 2
#> x y
#> <dbl> <chr>
#> 1 1 a
#> 2 2 NA
df %>% replace_na(list(x = 0, y = "unknown"))
#> # A tibble: 3 × 2
#> x y
#> <dbl> <chr>
#> 1 1 a
#> 2 2 unknown
#> 3 0 b
df %>% fill(x, y)
#> # A tibble: 3 × 2
#> x y
#> <dbl> <chr>
#> 1 1 a
#> 2 2 a
#> 3 2 b11.4 dplyr
O dplyr é “a grammar of data manipulation, providing a consistent set of verbs that help you solve the most common data manipulation challenges”.
Veja:
- O tutorial.
- A cheatsheet.
Aqui, temos as caixinhas:
- Subset
- Operate
- Reorder
- Rename
- Combine
- Summarize
- E tudo isso com groups
11.4.1 Subset - Linhas
Casos especiais:
starwars %>% filter(!duplicated(mass))
starwars %>% distinct(mass, .keep_all = TRUE)11.4.3 Operate
rows_*():
data <- tibble(a = 1:3, b = letters[1:3], c = 0.5 + 0:2)
rows_insert(data, tibble(a = 4, b = "z"))
#> # A tibble: 4 × 3
#> a b c
#> <int> <chr> <dbl>
#> 1 1 a 0.5
#> 2 2 b 1.5
#> 3 3 NA 2.5
#> 4 4 z NA 11.4.4 Reorder
select() funciona! Mas também temos relocate():
11.4.5 Rename
A filosofia do tidyverse é não utilizar rownames (“metadata is data”). Portanto, temos funções para renomear colunas, rename() e rename_with():
rename(iris, petal_length = Petal.Length)
rename_with(iris, toupper)11.4.6 Summarize
summarise(), resumir toda a informação em uma linha:
reframe() mais raro, mais de uma linha de resumo:
11.4.7 Combine
cbind() une as colunas de dois dataframes com as “mesmas” linhas. rbind une as linhas de dois dataframes com as “mesmas” colunas.
bind_cols() e bind_rows() são as versões do dplyr, e unem qualquer quantidade de dataframes.
E se as linhas não forem as mesmas? Precisamos de um merge/join: inner_join(), left_join(), right_join(), full_join().
11.4.8 Across
Como visto em select(), temos uma série de tidyverse selection helpers que podem ser utilizados para selecionar colunas.
Esses mesmos seletores podem ser utilizados em outros verbos, via across():
11.4.9 Groups
Um grupo pra cada linha: rowwise().