import numpy as npVisualização de Dados
Aqui falarei sobre a manipulação e visualização que a modelagem demanda. Porém, o material melhor estará no livro de R, RFCD, dado a disponibilidade do tidyverse. Aqui, comentarei muito mais rapidamente sobre as contrapartes no Python.
12 1. Numpy
12.1 1.1 Introdução
O que é Numpy? De acordo com o site oficial:
NumPy is the fundamental package for scientific computing in Python. It is a Python library that provides a multidimensional array object, various derived objects (such as masked arrays and matrices), and an assortment of routines for fast operations on arrays, including mathematical, logical, shape manipulation, sorting, selecting, I/O, discrete Fourier transforms, basic linear algebra, basic statistical operations, random simulation and much more.
Antes de tudo, vamos instalar e carregar a biblioteca:
12.1.1 O conceito de arrays
O conceito que encapsula as principais novidades que a biblioteca traz é o de array, e sua diferença com listas.
Em termos simplificados, podemos entender os arrays como um novo tipo de coleção, uma coleção homogênea/atômica, em oposição à listas, heterogêneas/genéricas. Isto é: todos os elementos de um array são do mesmo “tipo”, o que não é uma necessidade em listas.
Veja exemplos abaixo, e se poderão ou não ser entendidos como arrays:
[1]poderá.[1, 2]poderá.[1, "a"]não poderá, tem elementos de tipos diferentes.[1, [1, 2]]não poderá, tem elementos de tipos diferentes (inteiro e uma coleção).
Alguns exemplos mais complexos:
[[1, 2], [3, 4]]poderá! Arrays podem “conter si mesmos”, mas, especialmente, entenda isso como arrays podem ser “organizados em múltiplas dimensões”. No caso, seria um array bidimensional, uma matriz com linhas e colunas.[[1, 2], [3, 4, 5]]não poderá! Essa é outra novidade, os arrays devem ser “retangulares”, dentro de cada dimensão, todos os elementos devem ter o memso tamanho. Isso ficará mais claro a diante.- E
[[1, 2], [3, "a"]]? Não poderá. Tudo dentro de um array tem que ter o mesmo tipo. Também podemos pensar que, dentro de uma dimensão, tudo deve poder ser entendida como um array.
Ok, então, um array é um caso específico de uma lista, é uma lista com duas restrições:
- Todos os elementos devem ter o mesmo “tipo”.
- Deve ser retangulares.
12.1.2 Benefícios do numpy
Porque isso é útil? O que ganhamos com essa perda de generalização?
Na vida real, muitas vezes nos deparamos com esse tipo de dado. Em bases de dado, normalmente cada coluna é uma variável, uma coleção de valores de um mesmo tipo. Além disso, são incontáveis os lugares onde matrizes aparecem, e não apenas as bidimensionais.
Criar um framework que seja especializado nesses casos gera três benefícios principais:
- O clássico trade-off especialização-qualificação, o numpy é muito eficiente em realizar operações com esse tipo de dado. E o essa é uma das maiores propagandas que o numpy faz.
- Inclusive, por trás dos panos, a nível técnico, arrays são objetos bem diferentes de listas.
- A criação de ferramentas especialmente intuitivas e úteis para o contexto.
- Facilitação do escopo, fica muito mais simples e intuitivo elencar as ferramentas que queremos ter para trabalhar.
- Pense em como buscar as ferramentas relevantes para limpar uma base de dados, na documentação dos métodos de listas e bibliotecas math, stat, etc. Versus buscar as ferramentas na documentação do numpy.
12.1.3 Vetorização
A principal ferramenta/conceito criada para o contexto, para o “modo de pensar com arrays” é a vetorização.
Eu tenho certeza que vocês já tentaram fazer algo como [1, 2, 3] * 2, e tiveram vontade de desistir da programação ao ver que o resultado foi [1, 2, 3, 1, 2, 3] e não [2, 4, 6].
Porque isso acontece? Lembre que listas são genéricas: é óbvio o que [1, "a", [3, 4]] * 2 deveria retornar? Não! Para cada elemento, o símbolo * é o mesmo, mas as operações são completamente diferentes. Não é tão natural aplicar transformações elemento-a-elemento em coleções genéricas.
Agora, arrays, são homogêneos, é muito mais natural aplicar uma transformação elemento-a-elemento. Normalmente, quando estamos trabalhando com arrays, é porque é esse o tipo de transformação que queremos fazer. O numpy sabe disso, e as faz de um jeito muito eficiente. Esse é o conceito de transformações vetorizadas.
Vamos deixar isso mais claro com exemplos. Mas antes, veja um exemplo do ganho de eficiência com a vetorização:
n = 10000000
a1 = np.arange(n)
l1 = list(range(n))
%timeit a1 * 2
%timeit [x * 2 for x in l1]12.2 1.2 Básico sobre arrays
12.2.1 Criação e forma
Para criar arrays, use a função numpy.array:
a1 = np.array([1, 1, 1])
a2 = np.array([[1, 0, 1], [3, 4, 1]])
a3 = np.array([[[1, 7, 9], [5, 9, 3]], [[3,2,1], [4,5,6]]])
for a in [a1, a2, a3]: print(a, "\n")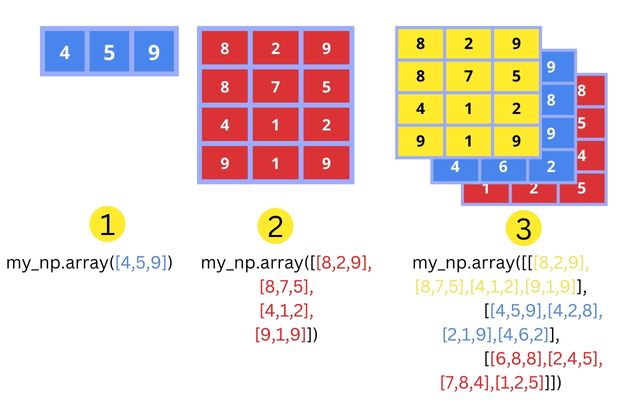
Note que começamos a “contar” pelo vetor, depois pelas linhas, depois pelas matrizes, etc.
Para estudar o formato de um array, usamos .shape. Também podemos usar as funções len(), e .ndim:
for a in [a1, a2, a3]: print(a.shape, a.ndim, len(a), sep = " -- ")Arrays são costumeiramente chamados de ndarrays, arrays n dimensionais.
Arrays importados
Podemos salvar arrays em arquivos, usando funções como:
- numpy.save: salva como um “arquivo array” “.npy”.
- numpy.savetxt: salva como um arquivo CSV, adequado apenas para arrays 1D e 2D.
- A biblioteca pickle: uma bilbioteca que consegue “conservar” qualquer objeto do python, mas pode ser demorado.
Similarmente, podemos importar arquivos, com funções numpy.load e numpy.loadtxt.
Por fim, é comum converter outros objetos em arrays. Veja as funções numpy.asarray e pandas.Series.to_numpy.
Arrays placeholders
Também podemos criar arrays com valores comuns, temos várias funções, como:
- numpy.empty: cria um array vazio com a forma especificada.
- numpy.ones: cria um array preenchido com uns.
- numpy.zeros: cria um array preenchido com zeros.
- numpy.full: cria um array preenchido com um valor constante.
- numpy.eye: cria uma matriz identidade.
- numpy.linspace: cria um array com valores espaçados uniformemente dentro de um intervalo.
- numpy.arange: cria um array com valores espaçados uniformemente dentro de um intervalo especificado.
print("Empty: \n", np.empty((2, 3)), "\n")
print("Ones: \n", np.ones((2, 3)), "\n")
print("Zeros: \n", np.zeros((2, 3)), "\n")
print("Full: \n", np.full((2, 3), 5), "\n")
print("Eye: \n", np.eye(3), "\n")
print("Linspace: \n", np.linspace(0, 10, num=5), "\n")
print("Arange: \n", np.arange(0, 10, 2), "\n")Para mais informação sobre criação de arrays, veja API Ref. → Routines → Array creation:
12.2.2 Random
O numpy tem uma parte da biblioteca focada na geração de números aleatórios, numpy.random. Se tiver curiosidade, leia mais sobre como computadores geram números pseudo-aleatórios.
Todas as distribuições que você pensar podem ser geradas pelo numpy:
- Uniforme: numpy.random.uniform.
- Uniforme 0-1: numpy.random.random.
- Uniforme discreta A-B: numpy.random.integers.
- Binomial: numpy.random.binomial.
- Normal: numpy.random.normal.
- Poisson: numpy.random.poisson.
- Samplear um array: numpy.random.choice.
print(np.random.uniform(0, 1, 5), "\n")
print(np.random.normal(0, 1, size=(3, 3)))12.2.3 Tipos de arrays
Mais cedo, falamos que todos os elementos de um arrays tem sempre o mesmo “tipo”. Em termos simplificados, o nome normalmente associado à “tipo” é dtype.
Um elemento (um “escalar”) pode ter vários tipos, mas os mais comuns são:
int_: números inteiros (integer).float_: números de ponto flutuante (floating-point). O tipo padrão.bool_: valores booleanos (TrueouFalse).str_: strings de texto.- E outros menos utilizados:
complex_: números complexos,object_: objetos Python genéricos,datetime64: datas e horários,timedelta64: diferenças entre datas e horários,category: categorias ou rótulos.
Alguns comentários mais técnicos:
Na realidade, embora exista o conceito de “número inteiro”, e o Python só defina um tipo de dado integer, existem muitas maneiras de representar um número na memória do computador. O numpy se importa com isso, e existem vários tipos para cada um dos conceitos acima.
- Por conta disso, o dtype pode aparecer com nomes diferentes como int64.
- Se você for muito nerd, talvez isso importe para o seu projeto. Para escolher um tipo específico use a função
np.arraycom o argumentodtype = .... Leia mais sobre isso aqui. - O tipo de um array
xpode ser descoberto comx.dtypeex.dtype.name.
Mas e se eu tentar criar o array [1, "a"]? O numpy usa coerção, ele converte todos os elementos a um mesmo tipo, de acordo com uma lista de prioridade. De maneira simples, int → float → string. Você também pode converter um array para outro tipo usando o método x.astype(). Veja exemplos abaixo.
print(np.array([[1,2], [3.0, 4]]), "\n")
print(np.array([[1,2], [3.0, "4.0"]]), "\n")
print(np.array([[1,2], [3, 4]], dtype = np.complex_), "\n")
print(np.array([[1,2], [3, 4]]).astype(str), "\n")Para mais informações sobre arrays, como funcionam, como são salvos na memória, veja API Ref. → Array objects. Cuidado, muitos temas técnicos e desnecessários (para o momento).
Especialmente, foram ignorados dois tópicos de arrays:
- Os masked arrays, arrays com valores faltantes, API Ref. → Array objects → Masked arrays.
- E os datetime arrays, arrays de datas, API Ref. → Array objects → Datetimes and Timedeltas.
12.2.4 Métodos
Na aula passada vocês aprenderam que no Python, a maior parte dos construtos da linguagem são classes, e isso não é exceção para os ndarrays. Cada array é um objeto, uma instância dessa classe, e tem seus métodos.
A lista completa de métodos pode ser vista na documentação da classe. Alguns interessantes são:
.tolist()..sum()e.prod();.cumsum()e.cumprod()..all()e.any()..max()e.min();.argmax()e.argmin().mean(),.var()e.std()..sort();.argsort()..choose()..round().- Em breve, vamos falar um pouco mais sobre:
.resise(),.reshape(), e.transpose();flatten()e.ravel()..copy()e.view().
12.3 1.3 Operações com Arrays
Lembre-se que o ponto mais importante é a vetorização. O numpy define “funções universais”, funções que podem ser aplicadas de forma vetorizadas.
Os exemplos abaixo são bem expositivos, são as funções que vocês já conhecem, apresentadas rapidamente.
12.3.0.1 Operações aritmétricas
Veja mais em API Ref. → Routines → Mathematical functions.
a1, a2 = np.array([1,2,3]), np.array([4,5,6])
print(np.subtract(a1, a2), "\n") #a1 + a2
print(np.divide(a1, a2), "\n") #a1 * a2
print(np.exp(a1), "\n")
print(np.sqrt(a1), "\n")
print(np.sin(a1), "\n")
print(np.log(a1), "\n")Também considere as constantes abaixo. Mais informações em API Ref. → Constants.
np.pi, np.e, np.nan, np.inf12.3.0.2 Operações matriciais
Veja mais em API Ref. → Routines → Linear algebra.
a1, a2 = np.array([(1,2), (-1,-3)]), np.array([(4,5), (-4,-6)]) # Note o uso, indiferenciável, de tuplas
print(a1 * a2, "\n")
print(np.dot(a1, a2), "\n") #a1 @ a2
print(np.linalg.matrix_power(a1, 3), "\n")
print(np.linalg.det(a1), "\n")
print(np.linalg.inv(a1), "\n")
print(np.linalg.norm(a1), "\n")
print(np.linalg.eig(a1), "\n")12.3.0.3 Operações com strings
Veja mais em API Ref. → Routines → String operations.
a1, a2 = np.array(['olá', 'oi', 'oopa']), np.array([', tudo bem?', ', bem?', ', bão?'])
print(np.char.add(a1, a2), "\n")
print(np.char.multiply(a1, [3, 1, 2]), "\n")
print(np.char.capitalize(a1), "\n")
print(np.char.count(a1, 'o'), "\n")
print(np.char.find(a1, 'o'), "\n")12.3.0.4 Operações lógicas/de comparação
Veja mais em API Ref. → Routines → Logic functions. Também veja operações de sets em API Ref. → Routines → Set functions.
a1, a2 = np.array([(1,2), (-1,-3)]), np.array([(4,5), (-4,-6)])
print(np.greater(a1, a2), "\n") #a1 > a2
print((a1 == a2).any(), "\n") #note the usage of ()
print(np.logical_or(a1 > 1, a2 < 0), "\n") #a1 > 1 or a2 < 012.3.0.5 Operações estatísticas
Veja mais em API Ref. → Routines → Statistics.
a1 = np.random.normal(0, 1, 100000)
a2 = a1 + np.random.normal(0, 0.5, 100000)
print(np.mean(a1), "\n")
print(np.median(a1), "\n")
print(np.std(a1), "\n")
print(np.quantile(a1, 0.25), "\n")
print(np.corrcoef(a1, a2), "\n")12.4 1.4 Subsetting e Copying
A referência básica está em User guide → Indexing on ndarrays.
A indexação de arrays é feita de forma similar à listas, com a1[algo]. A maioria das técnicas disponíveis para listas está disponível aqui também.
Essa parte é bem útil, porque lógicas similares de indexação podem ser utilizadas no pandas e em listas.
12.4.1 Subseting básico
Com uma dimensão, é simples. Conseguimos utilizar a técnica de indexes negativos.
a1 = np.array([1, 2, 3, 4])
print(a1, "\n")
print(a1[0])
print(a1[-1])E com duas dimensões? Agora, temos que informar o que queremos pegar de cada dimensão, a2[algo1, algo2]:
a2 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(a2, "\n")
print(a2[0, 1])E se eu quiser selecionar mais do que um elemento? Aqui, também é possível utilizar a técnica de slicing :.
print(a1[1:3])
print(a1[1:])
print(a1[:2])
print(a1[:])Com duas dimensões é a mesma ideia, lembrando que precisamos falar o que queremos pegar de ambas as dimensões, as possibilidades aumentam.
print(a2[0, 0:2])
print(a2[0:2, 1])
print(a2[1:, :])Com n dimensões é a mesma ideia, com uma entrada em [] para cada dimensão.
Se tiver curiosidade, veja dois truques usando ... e None nos índices aqui.
an = np.arange(3**3).reshape(3, 3, 3)
print(an[2, 2, 2])
print(an[0, :, :])Quando você ficar pica, vai descobrir que dá para omitir dimensões, como abaixo. Mas por enquanto, não inventa, coloque um “algo” para cada dimensão, nem que o “algo” seja “selecione tudo” (:).
print(a3[0:])Note que essa noção do subset deixa claro qual é a “ordem” dos componentes de um array multidimensional. Isto é, quando pedimos for i in a3, o que será passado para i? Cada elemento? Cada coluna, cada linha? cada matriz?
for i in a3:
for j in mat:
for k in row: print(i)Vemos que, do array tridimensional a3, i são as sub-matrizes, j são as linhas de uma sub-matriz, e i os elementos de cada linha. Isto é, a ordem é da maior/última/mais alta dimensão para a menor/mais baixa.
12.4.2 Subseting avançado
E se os índices que você quer obter estão em uma coleção? Podemos utilizar coleções de inteiros ou booleanos para acessar índices também!
print(a1[np.array([1, 2])]) #a1[[1, 2]]
a1[np.array([True, False, False, True])] #print(a1[[True, False, False, True]])Note que para booleanos, o índice-coleção precisa ser do mesmo tamanho da dimensão relevante.
O legal, é que da para utilizar isso para criar filtros:
print(a1[a1 + 1 > 2])Existem muitas outras técnicas utilizando essas ferramentas. Veja mais aqui.
12.4.3 Copy versus view
Um último comentário técnico, eu juro!
E aquela história insuportável de x = ..., y = x, e uma mudança inocente em y quebrando seu código porque x mudou também? Como fica isso no numpy?
Segue existindo 😴. Vou falar uma das frases já faladas abaixo, mas não se assuste.
No python, variáveis sempre são nomes referenciados a valores, mutating um valor – diferente de rebinding um valor – mostrará essa mudança em todos os nomes associados à ele.
Isto é, essa questão é bem geral no python. Infelizmente, não é hora de entrar em detalhes na lógica por trás de tudo isso. Para saber mais, eu gosto muito desse post.
O que precisamos saber agora é que sim, ainda estamos preocupados em criar .copy()’s dos arrays. Como uma regra de bolso, a menos que você de fato queira a referência ao objeto original, adicione o .copy().
Note que essa questão está bem presente: quando fazemos y = x[1, :], y é uma cópia ou uma referência? Não é obvio, e varia de caso a caso. Não vou entrar em detalhes, mas o ponto é, tome cuidado, e use cópias sem medo.
Um último ponto, que também não merece detalhe, é a existência de uma “semi-cópia”, ou shallow-copy, x.view(). Quais são as diferenças, quando eu uso um ou o outro? Meia noite eu te conto. Brincadeira, mas realmente, não vale falar sobre isso agora.
Fim!
Pronto! Vocês aprenderam o básico de numpy! Agora, podemos aplicar esse novo jeito de pensar para bases de dados, e conhecer a biblioteca especializada nisso, o pandas. Especialmente, relembre do que aprendemos, sobre a maneira de se pensar em dados vetorizados.
Existem dois temas adicionais, manipulação de arrays (mudar o formato, adicionar itens, combinar, e dividir), e funções universais (tecnicas poderosas que as funções do numpy habilitam).
13 2. Pandas
13.1 2.1 Introdução
O site oficial da biblioteca Pandas introduz ela da seguinte forma:
“Pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real-world data analysis in Python. (…) Pandas is built on top of NumPy and is intended to integrate well within a scientific computing environment with many other 3rd party libraries.”
Veremos nessa aula as mais diversas aplicações dessa biblioteca e seremos apresentados a “tipos” de dados semelhantes aos vistos anteriormente, porém, no Pandas.
Vamos começar!
Para instalação da biblioteca, basta utilizar do código de instalação:
# pip install pandasEm caso de dúvidas, recomendamos acessar a aba de instalação do site: https://pandas.pydata.org/docs/getting_started/install.html
13.1.1 Benefícios do Pandas:
Você está buscando uma maneira eficiente e poderosa de manipular e analisar dados em Python? Apresentamos o Pandas, a biblioteca que revoluciona a forma como lidamos com dados tabulares! É a escolha ideal para qualquer pessoa que deseja realizar análises de dados de maneira eficiente, flexível e poderosa em Python.
Alguns pontos de destaque da biblioteca são:
Facilidade de Uso: Manipule dados de forma simples e intuitiva, com estruturas de dados familiares como DataFrames e Séries, sem a complexidade de lidar diretamente com arrays ou listas.
Flexibilidade de Dados: Armazene e trabalhe com dados de diferentes tipos (números, strings, datas, booleanos) em uma única estrutura.
Operações Eficientes: Realize operações de manipulação de dados de forma rápida e eficiente, incluindo seleção, filtragem, ordenação, agrupamento, agregação e junção de dados de diferentes fontes.
Tratamento de Dados Ausentes: Lide facilmente com valores ausentes (NaN) em seus dados, com métodos integrados para detecção, preenchimento, remoção ou substituição desses valores, garantindo a integridade dos seus resultados.
Integração com Outras Ferramentas: Importe e exporte dados de e para uma variedade de formatos, como CSV, Excel, SQL, JSON, HTML, entre outros, facilitando a integração com outras ferramentas e sistemas.
Comunidade Ativa e Suporte: Faça parte de uma comunidade vibrante de usuários, com vasta documentação, tutoriais e suporte online, garantindo que você tenha o apoio necessário para aproveitar ao máximo o potencial do Pandas.
13.1.1.1 Series e dataframe:
O pandas se beneficia do uso de duas estruturas de dados principais (que se assemelham, até certo ponto, aos arrays que vimos anteriormente).
A primeira delas, nomeada de Series, é uma estrutura de dados unidimensional que pode conter qualquer tipo de dado, sendo semelhante a uma matriz unidimensional ou a uma coluna em uma tabela.
O dataframe se difere das Series por ser uma estrutura de dados bidimencional que se organiza em linhas e colunas, semelhantes a uma tabela de banco de dados ou uma planilha do Excel, e são muito usados em ciência de dados, análises financeiras, pesquisas acadêmicas, entre outros.
13.2 2.2 Básico Sobre Series e Dataframes
13.2.1 Como podemos criar essas estruturas de dados?
Para montarmos uma Series, utilizamos do comando pandas.Series(dados). Tenham em mente que esses dados podem estar em listas, dicinários, arrays…
import pandas as pd
s = pd.Series({"a":["a", "do", "le", "ta"],"b":["baby","shark"]})
s2 = pd.Series([1,2,3,4,"a"])
s3 = pd.Series([1,2]) #cria um index + dados
s4 = pd.Series([3,4],[7,8]) # usa o primeiro como dado + segundo como index
s4Já ao montarmos um DataFrame, usamos o comando pd.DataFrame(dados). Esses dados tem que ter o mesmo tamanho (lenght) para que possa ser criado.
df = pd.DataFrame({"a":["a", "do", "le", "ta"], "b":["baby","shark","tutu","tuturu"]})
#dfErrado = pd.DataFrame({"e":["r","r","a","d","o"], "E":["r","r","o"]})
df# Podemos, também, montar "na marra" o Data Frame:
df = pd.DataFrame([[19, 0, "F"], [20, 1, "F"], [60, 2, "M"]], index=["Júlia", "Mariana", "Antonio"], columns=['Nome', 'Filhos', 'Sexo'])
df13.2.2 Outras Fontes:
Podemos, a partir de dados da internet ou coleta de dados manuais, usar o Pandas para acessar base de dados. Segue alguns exemplos:
pd.read_excel(arquivo)
pd.read_CVS(arquivo)
pd.read_sql(arquivo)
Obs: o “arquivo” se refere a um url do arquivo ou um “endereço” de arquivo no computador do usuário.
Mais ferramentas: https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html
13.2.3 Summarise:
De forma geral, temos algumas ferramentas principais para condensar dados com diferentes objetivos.
Antes disso, veremos alguma ferramentas úteis para possíveis estudos da base:
- Número de Linhas e colunas no dataframe:
df.shapedf["valor"].value_counts() #retorna um número inteiro- Número de valores únicos em uma coluna:
df["coluna"].nunique()- Estatísticas e Bescrições Básicas para cada coluna:
df.describe()O pandas fornece um grande conjunto de funções de resumo que operam em diferentes tipos de objetos do pandas (colunas de DataFrame, Series, GroupBy, Expanding e Rolling (ver abaixo)) e produzem valores únicos para cada um dos grupos. Quando aplicado a um DataFrame, o resultado é retornado como uma Series do pandas para cada coluna.
Importante: verifique o link oficial da página para saber mais
13.2.3.1 Group Data:
O “Group Data” (ou “Agrupamento de Dados”) na biblioteca Pandas refere-se a uma operação fundamental de análise de dados, na qual você divide um conjunto de dados em grupos com base em determinados critérios e, em seguida, aplica operações ou funções a esses grupos. Isso é feito principalmente usando o método .groupby() do Pandas.
Importante! Acesse https://pandas.pydata.org/pandas-docs/stable/user_guide/groupby.html para saber mais.
13.3 2.3 Subset
Os subconjuntos são porções específicas de um DataFrame que podem ser selecionadas com base em critérios como linhas, colunas ou ambos.
Existem três tipos principais de subconjuntos: linhas, colunas e linhas e colunas simultaneamente.
13.3.1 Subset linhas
Para estudarmos os tópicos abaixo, vamos usar uma planilha fictícia.
import pandas as pd
arquivo = "Clientes.xlsx"
df = pd.read_excel(arquivo)
dfNesse exemplo, a base de dados é extremamente pequena então não temos problema em rodarmos os dados. Em casos mais complexos, podemos pedir que o programa rode apenas os dados que precisamos para a manipulação.
#Podemos apenas rodar a primeira linha (rótulos das colunas) quando a base é muito grande
df.head()
#ou as primeiras x linhas
df.head(2)
#ou as últimas x linhas
df.tail()
df.tail(3)Para mostrar alguma das fórmulas que temos a nossa disposição, vamos imaginar que você é estagiário desse estabelecimento: quais dados podemos tirar dessa tabela?
#Primeiramente, vamos ver se os dados respeitam uma sequência lógica
subset1 = df[df["Idade"]<100] #não faz sentido ter uma pessoa de mais de 100 anos
subset2 = subset1[subset1["Idade"] > 18] #não faz sentido um "cliente" ser menor de idade
subset3 = subset2.drop(columns = "Nome.1")
DF = subset3
DF#agora, vamos analisar mais a fundo a tabela:
Inad = DF[DF["Inadimplente"] == True] #mais pra frente, ainda nessa aula, aprenderemos uma maneria relativamente mais simples para fazer isso (query)
NãoInad = DF[DF["Inadimplente"] == False]
InadMaior = DF[(DF["Inadimplente"] == True) & (DF["Idade"] > 18)] #nessa base de dados, nós já tiramos os Inad menores de idade mas vale o exemplo
Estado = DF[(DF["Estado"] == "SP") | (DF["Estado"] == "TO")]
MaisVelhos = DF.nlargest(3,"Idade")
MaisNovos = DF.nsmallest(3,"Idade")
#Inad
#NãoInad
#InadMaior
#Estado
#MaisNovos
#MaisVelhosDa mesma forma que podemos selecionar com base nos critérios selecionados, podemos usar de funções que aleatorizem os dados:
DF.sample(frac = 0.5) #aqui, pedimos para que o programa nos recorte uma fração aleatória do dataframeDF.sample(n=9) #ou podemos dar um valor para o tamanho da amostra aleatóriaOutra ferramenta para essas seleções é a query. Seu maior diferencial é que essa ferramenta permite usar a lógica Booleana para filtrar as linhas.
#A lógica booleana faz com que o critério de seleção seja verificar se uma afirmação, a nossa escolha, é verdadeira ou falsa
DF.query('Idade > 50') #ele seleciona cada linha que a resposta de Idade>50 == True
DF.query('Nome.str.len() > 5') #ele seleciona cada linha cujo comprimento do nome seja maior que 5
DF.query('Idade > 40 and Estado == "SP"')
DF.query('Inadimplente == True and Dívida > 1000')
DF.query('Nome.str.startswith("B")')13.3.2 Subset colunas
Agora, vamos avançar para o próximo passo e aprender como criar subconjuntos de colunas. Os subconjuntos de colunas nos permitem focar em variáveis específicas dos nossos dados, facilitando a análise e visualização de informações relevantes.
# Para selecionar apenas algumas colunas, temos um "modelo" base que seguimos
DF["Nome"]
DF.Nome
DF[["Nome","Idade"]]
DF[["Nome","Inadimplente","Dívida"]]
#e se quisermos o nome e a dívida dos inadimplentes?
Corte1 = DF[["Nome", "Inadimplente", "Dívida"]]
Corte2 = Corte1[DF["Inadimplente"] == True]
Corte3 = Corte2[["Nome", "Dívida"]]
Corte313.3.3 Subset os dois juntos
Nós vimos que podemos manipular a base de dados de forma a filtrarmos linhas e colunas de forma individual. Agora, veremos algumas funções que unificam essas tarefas, ou seja, atua com as colunas e linhas.
13.3.3.1 iloc e loc:
Começando pelo iloc, essa função é usada para acessar os dados de um DataFrame usando índices inteiros. Você pode usar o iloc para selecionar linhas e colunas com base em sua posição numérica no DataFrame. Ou seja, temos a posição do que queremos e usamos ele para selecionar o necessário.
Já o loc é usado para acessar os dados de um DataFrame usando rótulos de índice. O loc permite selecionar linhas e colunas com base nos rótulos definidos para o índice e as colunas. Ou seja, sabemos o que queremos mas buscamos sua posição.
#DF.iloc[1,0] #linha da posição 1 (segunda linha) na coluna de posição 0 (primeira coluna)
#DF.iloc[10:20] #Select rows 10-20.
DF.iloc[:, [1, 2, 4]] #Select columns in positions 1, 2 and 5 e todas as linhas
DF.iloc[[0,5,10,15],:] #Seleciona as linhas nas posições 0, 5, 10 e 15 e todas as colunasDF.loc[:, 'Idade':'Inadimplente'] #Select all columns between x2 and x4 (inclusive).
DF.loc["Jaime":"Fred", :] #Seleciona todas as linhas entre "Jaime" e "Fred"
DF.loc[df['Idade'] > 10, ['Inadimplente', 'Estado']] #Select rows meeting logical condition, and only the specific columns .
#só as linhas que13.3.3.2 iat e at:
Essas ferramentas são semelhantes ao ‘iloc’ e ‘loc’ que vimos, mas são usados para acessar valores únicos em um DataFrame, seja usando índices inteiros (posições) ou rótulos de índice, respectivamente.
A ferramenta iat é mais eficiente para acesso baseado em posição, se baseando em índices para achar o valor, enquanto at é mais eficiente para acesso baseado em rótulos.
DF.iat[0,0] #primeira linha da primeira coluna
DF.iat[0,1] #primeira linha da segunda coluna
DF.iat[1,0] #segunda linha da primeira coluna
DF.iat[9,4] #décima linha da quinta colunaDF.at[0, "Idade"] #nós damos o rótulo/index e a coluna na qual ele deve procura-lo
#DF.at[3, "Nome"]Resumindo, use iloc/loc quando precisar acessar múltiplos valores ou fatias de dados e iat/at quando precisar acessar um único valor de forma eficiente. A escolha entre iloc/loc ou iat/at depende do tipo de operação que você está realizando e se está trabalhando com acessos únicos ou múltiplos no DataFrame.
Resumindo, use iloc/loc quando precisar acessar múltiplos valores ou fatias de dados e iat/at quando precisar acessar um único valor de forma eficiente. A escolha entre iloc/loc ou iat/at depende do tipo de operação que você está realizando e se está trabalhando com acessos únicos ou múltiplos no DataFrame.
13.4 2.4 Operar/Criar
13.4.0.1 Operações em colunas
data = {'A': [1, 2, 3],
'B': [4, 5, 6]}
df = pd.DataFrame(data)
df# Adicionando uma nova coluna
df['C'] = [7, 8, 9]
df# Renomeando uma coluna
df.rename(columns={'A': 'A_Novo'}, inplace=True)
df# Aplicando uma fórmula a uma coluna
df['B_quadrado'] = df['B'].apply(lambda x: x ** 2)
df['B/2'] = df['B'].apply(lambda x: x / 2)
df['A+2'] = df['A_Novo'] + 2
df['A-2'] = df['A_Novo'] - 2
df# Removendo uma coluna
df.drop(columns=['B_quadrado'], inplace = True)
df# Adicionando duas colunas e armazenando o resultado em uma nova coluna
df['A+B'] = df['A_Novo'] + df['B']
df# Encontrando a soma de uma coluna
soma_B = df['B'].sum()
soma_B# Encontrando a média de uma coluna
media_B = df['B'].mean()
media_B# Filtrando linhas com base em uma condição em uma coluna
df_filtrado = df[df['A_Novo'] > 2]
df_filtrado# Aplicando a função 'sqrt' a todos os elementos da coluna 'C'
import numpy as np
df['C'] = np.sqrt(df['C'])
df13.4.0.2 Operações em linhas e células
# Aplicando uma função em todas as linhas
soma_por_linha = df.sum(axis=1)
soma_por_linha# Selecionando uma célula específica
valor_celula = df.at[0, 'B']
valor_celula# Atualizando o valor de uma célula específica
df.at[0, 'B'] = 100
df# Aplicando uma função em uma célula específica
df.at[0, 'B'] = df.at[0, 'B'] * 2
df# Removendo uma linha pelo índice
df.drop(index=0, inplace=True)
df# Inserindo uma nova linha
data = {'A': [1, 2, 3],
'B': [4, 5, 6]}
df = pd.DataFrame(data)
# Novas linhas a serem adicionadas
novas_linhas = pd.DataFrame({'A': [10, 11], 'B': [20, 21]})
# Concatenando os dois DataFrames
df = pd.concat([df, novas_linhas], ignore_index=True)
df# Ordenando o DataFrame por uma coluna específica
df = df.sort_values(by='A')
df13.4.1 Lidar com dados NA
data2 = {'A': [1, 2, 3, 4],
'B': [np.nan, 6, 7, np.nan],
'C': [10, np.nan, np.nan, 13]}
df_na = pd.DataFrame(data2)# Encontrar valores NA (ausentes) em um DataFrame
df_na.isna()# Remover colunas com valores ausentes
df_na.dropna(axis=1, inplace=True)
df_na# Remover linhas com valores ausentes
df_na.dropna(axis=0, inplace=True)
df_na# Preencher valores NA com um valor específico (por exemplo, zero)
df_na.fillna(0, inplace=True)
df_na14 Temas Adicionais
14.1 1.5 Numpy - Manipulating Arrays
Existem outras quatro operações relacionadas a manipular arrays como um todo: alterar a forma, adicionar/remover elementos, combinar, e dividir. Essa parte não é tão importante, e as funções são simples, vamos vê-las rapdiamente.
14.1.1 Alterar a forma
Veja as funções/métodos:
.resize()ereshape(): para alterar a forma de um array, passando a nova forma como uma tupla.transpose(): transpor arrays..flatten()e.ravel(): achatar arrays.
14.1.2 Adicionar e remover elementos
Veja os funções:
append(),insert(), edelete().
14.1.3 Combinar
Veja as funções:
14.1.4 Dividir
Veja as funções:
14.2 1.6 Numpy - Funções Universais
Existe um último tópico interessante, mas mais avançado. As funções do numpy são bem poderosas e flexíveis. É possível:
- Aplicá-las para cada dimensão separadamente – usando o argumento
axis=. - Filtrar dimensões para não aplicar – usando o argumento
where= - Aplicar de modo a “acumular” ou “reduzir” o resultado – usando os métodos
.accumulate()e.reduce().
Aprendam sobre esses tópicos em Api Ref. ⭢ Universal functions. Adicionalmente, Também vejam algumas táticas avançadas em Api Ref. ⭢ Routines ⭢ Functional programming.
Abaixo apresento alguns exemplos sem contexto nenhum.
a1 = np.array([1,2,3])
np.add.accumulate(a1)
np.add.reduce(a1)a2 = np.array([[1,2], [4,5]])
print(np.add.accumulate(a2, axis = 0))
print(np.add.reduce(a2, axis = 0))where1 = [True, True, False]
where2 = [[True, False, False], [False, True, False], [False, False, True]]
print(np.add.reduce(a1, 0, where = where1), "\n")
print(np.add.reduce(a2, 0, where = where2), "\n")14.3 2.5 Pandas - Reshape
Primeiro, vamos baixar uns exemplos:
tables_links = {
'df1': 'https://raw.githubusercontent.com/tidyverse/tidyr/c6c126a61f67a10b5ab9ce6bb1d9dbbb7a380bbd/data-raw/table1.csv',
'df2': 'https://raw.githubusercontent.com/tidyverse/tidyr/c6c126a61f67a10b5ab9ce6bb1d9dbbb7a380bbd/data-raw/table2.csv',
'df3': 'https://raw.githubusercontent.com/tidyverse/tidyr/c6c126a61f67a10b5ab9ce6bb1d9dbbb7a380bbd/data-raw/table3.csv',
'df4a': 'https://raw.githubusercontent.com/tidyverse/tidyr/c6c126a61f67a10b5ab9ce6bb1d9dbbb7a380bbd/data-raw/table4a.csv',
'df4b': 'https://raw.githubusercontent.com/tidyverse/tidyr/c6c126a61f67a10b5ab9ce6bb1d9dbbb7a380bbd/data-raw/table4b.csv',
'df5': 'https://raw.githubusercontent.com/tidyverse/tidyr/c6c126a61f67a10b5ab9ce6bb1d9dbbb7a380bbd/data-raw/table6.csv'
}
for i in tables_links.keys():
globals()[i] = pd.read_csv(tables_links[i])14.3.1 Reordenar
Linhas:
df1.sort_values(by='cases', ascending=False)E colunas
df1.reindex(columns=['year', 'cases', 'population', 'country'])14.3.2 Renomear
Colunas:
df1.rename(columns={'cases': 'new_cases', 'population': 'new_population'}, inplace=False)Linhas:
df1.rename({0: 'Row1', 1: 'Row2', 2: 'Row3', 3: 'Row4', 4: 'Row5', 5: 'Row6'})14.3.3 Remodelar
Wide to long (melt):
print(df4a)
pd.melt(df4a, id_vars = ["country"], var_name = "year", value_name = "cases")Long to wide (pivot)
print(df2)
pd.pivot(df2, index = ["country", "year"], columns = "type", values = "count")14.3.4 Separar e unir colunas
Separar:
print(df3, "\n")
df3[["cases", "population"]] = df3["rate"].str.split("/", expand = True)
df3 = df3.drop("rate", axis = 1)
print(df3)Unir:
print(df5, "\n")
df5["year"] = df5["century"] + df5["year"]
df5 = df5.drop("century", axis = 1)
print(df5)14.4 2.6 Pandas - Combinar
14.4.1 Concatenar
Veja a função: - .concat()
14.4.2 Merge
Veja as funções abaixo para unir dataframes de maneiras diferentes:
Standard Joins:
Filtering Joints:
15 1. Introdução
Esta aula marca uma divisão no curso de trainee. Até agora, vocês estavam aprendendo várias ferramentas úteis, mas sem um objetivo específico além de simplesmente aprender a programar em Python. Nesta aula, vamos apresentar o objetivo, vocês irão aprender a realizar “projetos de Ciência de Dados”.
A aula está organizada como segue:
- 1 Introdução.
- 1.1 Recapitulando: vamos recapitular as ferramentas aprendidas até aqui, e trazer atenção para os conceitos/modos de pensar mais gerais, que motivaram essas ferramentas.
- 1.2 Projetos de ciência de dados: iremos apresentar o que é Ciência de Dados, e quais são as etapas de um projeto comum: data wrangle, exploração, e comunicação.
- 2 Data Wrangle.
- 2.1 Tidy: a primeira etapa de um projeto é “arrumar” os dados, e existe uma noção bem clara do que é tidy data. Vamos mostrar como as ferramentas do pandas podem ser utilizadas nessa etapa.
- 2.2 Transformação: após arrumar os dados, pode-mos transformá-los para habilitar as etapas da visualização e modelagem. Também iremos relacionar com as ferramentas do pandas.
- 3 Visualização: outra parte do ciclo é a visualização, tanto via summary statistics (3.1), quanto via gráficos (3.2). Vamos apresentar a biblioteca matplotlib e como utilizá-la nesse contexto.
15.1 1.1 Recapitulando
Nas três primeiras aulas do curso, vocês aprenderam diversas ferramentas. Veja o diagrama abaixo, e atente por:
- Relembrar as ferramentas em si.
- Tenha certeza que você de fato sabe todos esses temas.
- Agora com essa visão de cima, veja os conceitos mais gerais de ciência da computação associados às ferramentas.
- O foco do curso não foi explicar essas generalizações, mas elas são muito úteis, tanto para entender melhor como o python funciona, quanto para facilitar aprender outras linguagens no futuro.
- Veja como as ferramentas condicionam novas maneiras de pensar em dados/problemas.
- Na última aula, vocês aprenderam o conceito de vetores homogêneos, e o novo modo de pensar da vetorização. Mais especificamente, também aprenderam a maneira de pensar em “bases de dados”
Na aula de hoje, vocês vão aprender dois novos contextos: (i) um tipo específico de organização de bases de dados, os dados tidy, e (ii) a maneira de usar dados tidy para resolver problemas, com a Ciência de Dados, e as etapas de seus projetos.
Adicionalmente, vão ver novas ferramentas: para a parte de arrumação de dados, vocês já a conhecem, é o pandas, mas para a visualização, vão aprender a biblioteca gráfica matplotlib.

15.2 1.2 Projetos de Ciência de Dados
15.2.1 A Ciência de Dados
A Ciência de Dados é um campo gigante, que nasceu via uma demanda de expandir a estatística para vias de “learn from data”, “more emphasis on data preparation and presentation rather than statistical modeling”, e “emphasis on prediction rather than inference”. Atualmente, o termo não é super bem definido, e o campo tem muita intersecção com outras disciplinas.
De acordo com a Wikipedia:
Data science is an interdisciplinary academic field that uses statistics, scientific computing, scientific methods, processes, algorithms and systems to extract or extrapolate knowledge and insights from data.
Fontes: “50 Years of Data Science” (2017) e Wikipedia.
15.2.2 As etapas de um projeto
Mais interessante que ficar tentando definir a disciplina, vamos entendê-la na prática. Como a aula é minha, e eu faço o que eu quiser, vou utilizar a explicação do livro “R for Data Science”.
Um projeto comum, no geral, se parece como abaixo. Veja uma breve explicação de cada tópico.

15.2.2.1 Importing
A primeira etapa é a importação. Alguns comentários:
- Os dados podem vir de várias fontes, como arquivos locais, bancos de dados, APIs (application programming interface), ou de sites (via web scrapping).
- Os dados podem estar em vários formatos como CSV, Excel, JSON, entre outros. É interessante ter um conhecimento básico de como cada um funciona.
- Cada tipo de fonte tem uma maneira diferente de se interagir, e cada formato exige sua própria função. Para os casos mais simples, o pandas (e qualquer outra biblioteca de dataframes), tem funções para I/O.
Não vamos entrar em detalhes nesse tema. Não é algo super extenso nem complexo, e existem muitas referências online. Uma das mais completas que achei foi esse tutorial da RealPython.
15.2.2.2 Tidy
A próxima etapa é arrumar, tidy, os dados. Vamos falar sobre isso com mais detalhe, mas existe uma noção bem específica do que são dados arrumados, tidy data.
As três próximas etapas existem dentro de um ciclo.
15.2.2.3 Transform
Mesmo com dados já arrumados, ainda temos o interesse de transformá-los, para conseguir obter insights novos da mesma base de dados. Na aula de hoje, vamos dar alguns exemplos de interesses, e este tema ficará mais claro.
Visualizar e modelar os dados trará novos insights e novas demandas, de modo que estamos constantemente transformando os dados para criar novas visualizações e modelagens.
Tidy e transform juntos são chamados de data wrangling.
15.2.2.4 Visualize
Aqui, serei preguiçoso, o texto do Hadley Wickham é muito bom:
Visualisation is a fundamentally human activity. A good visualisation will show you things that you did not expect, or raise new questions about the data. A good visualisation might also hint that you’re asking the wrong question, or you need to collect different data. Visualisations can surprise you, but don’t scale particularly well because they require a human to interpret them.
15.2.2.5 Model
Um modelo é, em termos simplificados e a depender do contexto, um conjunto de hipóteses sobre o mundo – sobre o processo gerador dos dados –, acrescido com um método matemático e computacional de estimar esse processo.
Models are a fundamentally mathematical or computational tool, so they generally scale well. (…) But every model makes assumptions, and by its very nature a model cannot question its own assumptions. That means a model cannot fundamentally surprise you.
15.2.2.6 Comunication
O último passo é comunicação. As linguagens de programação provém ferramentas para expor seus resultados. O próprio Jupyter Notebook onde esta aula foi escrita é um exemplo disso. Mas existem muitas outras ferramentas mais avançadas para criar reports, livros, páginas na web, aplicativos, etc. No curso de trainee, não iremos cobrir essa etapa com detalhe.
Por fim, dos últimos comentários. Primeiro, e a programação?
Surrounding all these tools is programming. Programming is a cross-cutting tool that you use in every part of the project. You don’t need to be an expert programmer to be a data scientist, but learning more about programming pays off because becoming a better programmer allows you to automate common tasks, and solve new problems with greater ease.
E o que falta?
No curso do trainee iremos explicar todas as etapas (fora comunicação), mas é só isso que você precisará? Não, cada projeto exige seu conhecimento específico, em cada tema, cada disciplina, existem conceitos próprios que entrarão em alguma das etapas aqui descritas. Mas tudo bem, o importante é vocês saberem a base, e conseguirão ir atrás do adicional por conta própria.
15.2.3 A Organização de um script
Acima temos as etapas “teóricas” de um projeto, mas como um script é organizado na prática? Normalmente nas seguintes seções:
- Introdução:
- Descrição do problema.
- Descrição dos dados (fontes, questões técnicas, etc.).
- Setup do código (importar módulos, definir funções, etc.).
- Importar e arrumar:
- Importar os dados [importar].
- Transformá-los em um dataframe tidy [arrumar].
- Lidar com NAs [arrumar].
- Pré-processamento dos daods:
- Analisar cada variável, seu tipo, valores NA/NaN, e mais:
- Variáveis categóricas – categorias, distribuição [visualizar]..
- Variáveis numéricas – range, distribuição [vis.].
- Corrigir problemas observados [transformar].
- Analisar cada variável, seu tipo, valores NA/NaN, e mais:
- Análise exploratória:
- Explorar a relação entre as variáveis, especialmente entre os x’s e os y’s.
- Y binário: distribuição condicional em cada x [vis.].
- Y contínuo: distribuição conjunta em cada x [vis.].
- Conseguir insights sobre o problema e transformar/criar variáveis para a modelagem [trans.].
- Modelagem:
- Dividir base em treino e teste, balancear os dados [trans.].
- Definir os modelos e aplicá-los. Variar os hiperparâmetros [modelar].
- Visualizar os resultados [vis.].
- Adquirir insights, transformar os dados de acordo, e remodelar [trans.] [modelar].
- Comunicar:
- Gerar uma visualização final com os pontos principais do processo e principais resultados [vis.].
- Comunicar os resultados [comunicar].
Todas essas etapas serão explicadas na prática na aula 6, então não se preocupem tanto por enquanto.
16 2. Data Wrangle
16.0.1 Tidy
16.0.1.1 Tidy data
[You can represent the same underlying data in multiple ways. The example below shows the same data organised in four different ways. Each dataset shows the same values of four variables country, year, population, and cases, but each dataset organises the values in a different way.]


[These are all representations of the same underlying data, but they are not equally easy to use. One dataset, the tidy dataset, will be much easier to work with inside the tidyverse.
There are three interrelated rules which make a dataset tidy:
- Each variable must have its own column.
- Each observation must have its own row.
- Each value must have its own cell.
Figure 12.1 shows the rules visually. ]

[ Why ensure that your data is tidy? There are two main advantages:
There’s a general advantage to picking one consistent way of storing data. If you have a consistent data structure, it’s easier to learn the tools that work with it because they have an underlying uniformity.
There’s a specific advantage to placing variables in columns because it allows R’s vectorised nature to shine. As you learned in mutate and summary functions, most built-in R functions work with vectors of values. That makes transforming tidy data feel particularly natural. ]
16.0.1.2 Arrumando datasets
Agora que já entendemos o que é tidy data, podemos adquirir a habilidade de olhar para um dataset e, sabendo onde queremos chegar, elencar quais são as alterações a serem feitas – “remover esta linha”, “dividir essa coluna no meio”.
Após elencar quais alterações devem ser feitas, é simples fazer a ponte de quais manipulações de dados você quer fazer – “subset linhas” e “separar colunas”.
Por fim, só falta relembrar como é o código que aplica essa manipulação. Essa é a parte mais simples! É só voltar na aula passada, pesquisar na internet, ver no chat, ou perguntar para o seu amigo preferido!
Tendo as duas primeiras habilidades, você tem tudo o que precisa para pesquisar, e não há problema nenhum em ter que pesquisar, o problema é ter que pesquisar , e não saber como!. Agora, se você só sabe a terceira, você não precisa pesquisar, mas não sabe o que você não precisa pesquisar, o que não é especialmente útil.
Se você quiser ficar insano no pandas, rever a aula passada três vezes por dia, deitado numa banheira congelada, será ótimo, você ficará eficiênte muito rápidamente. Mas não precisa, essa eficiência vem com o tempo, e o mais importante é saber a lógica de “o que precisa alterar” e “quais são as manipulações que existem”.
Ok, sem mais delongas, vamos aprender a elencar alterações, vamos ver uns exemplos vide o PPT.
Qual foi a receitinha de bolo que aprendemos? (hmm bolo 😋). Recebemos um dataset, e:
- Arrumar os dados para o formato data frame.
- Todas as colunas são homogêneas?
- Remover linhas “ruins”, converter valores.
- Todas as colunas são do mesmo tamanho?
- Remover linhas “ruins”.
- Todas as colunas são homogêneas?
- Arrumar os dados para o formato tidy.
- Toda coluna é uma variável?
- Remover colunas “ruins”.
- Separar/unir colunas colunas.
- Toda linha é uma observação?
- Quais são as variáveis que definem uma observação?
- Pivot e melt.
- Toda célula é um valor?
- Transformar dados “ruins” em NA.
- Lidar com dados NA.
- Toda coluna é uma variável?
- Tenho mais de um dataset? Deixá-los tidy e então realizaram algum merge.
16.0.2 Transform
Após arrumarmos um dataset, ainda aplicaremos transformações com base nas demandas da fase de visualização e modelagem.
- Manipular linhas.
- Sorting.
- Sampling.
- Filtrar observações.
- Transformar/criar colunas:
- Alterar a unidade de uma variável.
- Normalizar variáveis.
- Agrupar as categorias de uma variável categórica.
- Corrigir/formatar texto de variáveis string.
- Manipular datas.
- Criar novas colunas a partir de operações com múltiplas outras Exemplos: salário semanal * semanas trabalhadas; idade ao quadrado.
- Criar uma coluna para ajudar em um plot.
Todas essas operações são factíveis de serem feitas com base na aula passada de pandas. Vocês verão muitos exemplos dessa etapa na aula 6.
17 3. Visualização
17.1 3.1 Sumarisação dos Dados
[Maneiras de conseguir “resumir” dados, criar estatísticas descritivas em cima de uma base de dado]
[Alguns links:
https://pandas.pydata.org/docs/getting_started/intro_tutorials/06_calculate_statistics.html https://www.geeksforgeeks.org/pandas-groupby-summarising-aggregating-and-grouping-data-in-python/ https://www.geeksforgeeks.org/pandas-groupby-summarising-aggregating-and-grouping-data-in-python/]
Vamos começar carregando dados:
import pandas as pddf = pd.read_csv("https://drive.google.com/uc?id=1u2MEH_DTBMyG3clVKA4Q5FEpntLZNKeE")
df17.1.1 Sumarisando o dataframe como um todo
[funções .info() e .describe(). tem mais alguma função tipo essas?]
17.1.2 Sumarisando variáveis categóricas
[explicar o .value_counts. mais algum método legal?]
counts = df['Fuel_Type'].value_counts(normalize = True)
print(counts)
counts.plot(kind = "bar")17.1.3 Sumarisando variáveis contínuas
[explicar as estatísticas de .describe, density, e boxplot. mais algum método legal?]
As estatísticas descritivas principais estão na tabela “describe”, mas também podem ser obtidas individualmente.
print(df['Price'].mean()) # Também existe .sum(), .min(), etc.
df['Price'].describe()De modo mais geral, mas menos mensurável, podemos olhar para a distribuição da variável como um todo, e uma visualização simplificada com boxplots.
df['Price'].plot.density()df['Price'].plot.box()17.1.4 Analisando grupos nos dados
[explicar fazer esses summaries com groupby, e usando o argumento by=… nas funções de plotting. ver https://www.shanelynn.ie/summarising-aggregation-and-grouping-data-in-python-pandas/ por exemplo]
[Parte do material abaixo ainda é composto de referências, e não é 100% autoral, mas tudo teve pelo menos contribuições pessoais.]
17.2 GGPlot
[a fazer]
17.3 Matplotlib
[a fazer]
[alguns links: https://matplotlib.org/stable/users/explain/quick_start.html; https://matplotlib.org/3.8.3/users/index.html; https://matplotlib.org/cheatsheets/_images/cheatsheets-1.png; https://matplotlib.org/3.8.3/index.html, https://matplotlib.org/3.8.3/api/index.html] ### Anatomia de uma figura
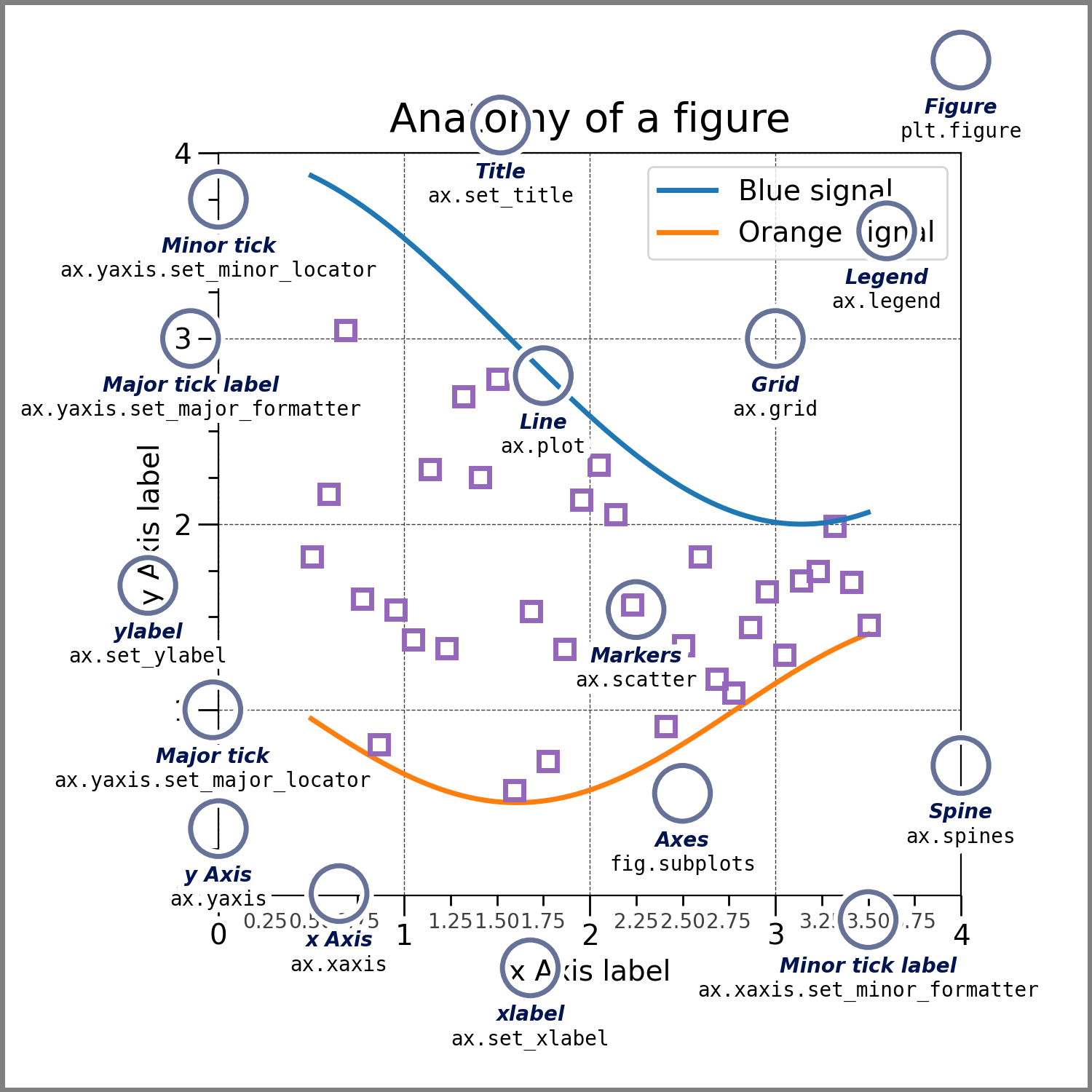
- Figure
- Axis
- Artist
[explicar isso dai] ### O estilo da programação
[explicar https://matplotlib.org/stable/users/explain/quick_start.html#coding-styles por cima e apresentar um exemplo) ### Plots
[explicar os plots possíveis] ### Estética
[alterando a estética dos dados, isto é, cores, markers, etc.] ### Tema
[alterando a estética da figura (não dos dados), isto é, eixos, título, etc.] ### Plots combinados
[subplots e tals]